World Journal of Engineering and Technology




Wake-Up-Word Feature Extraction on FPGA
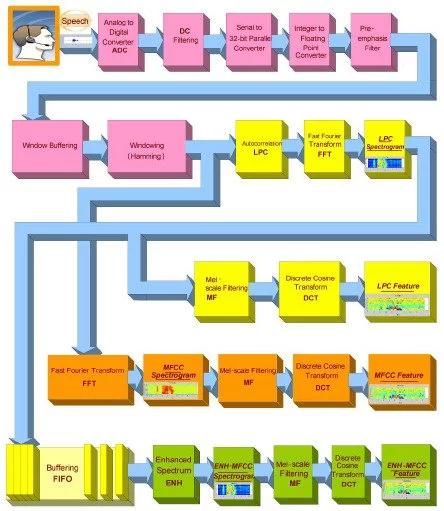
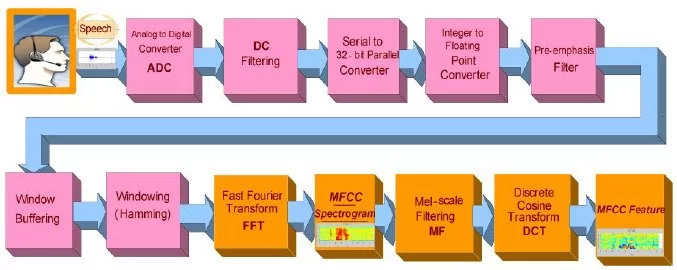
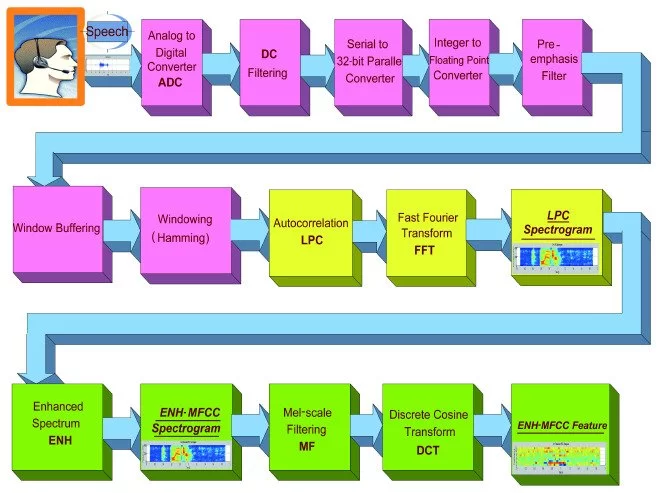
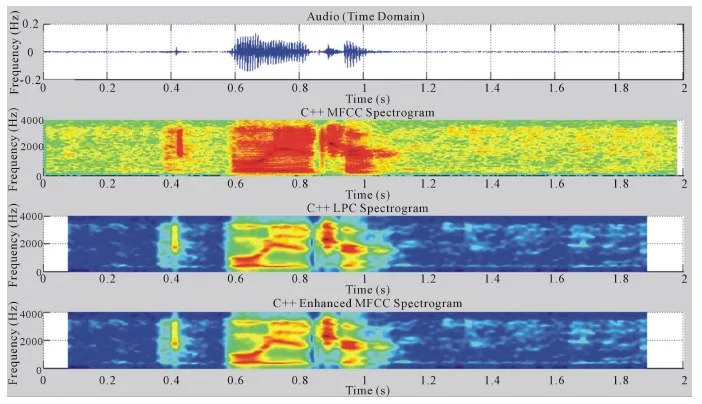
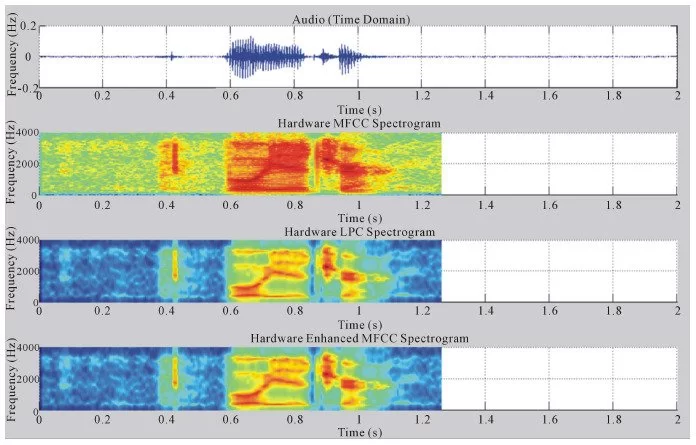
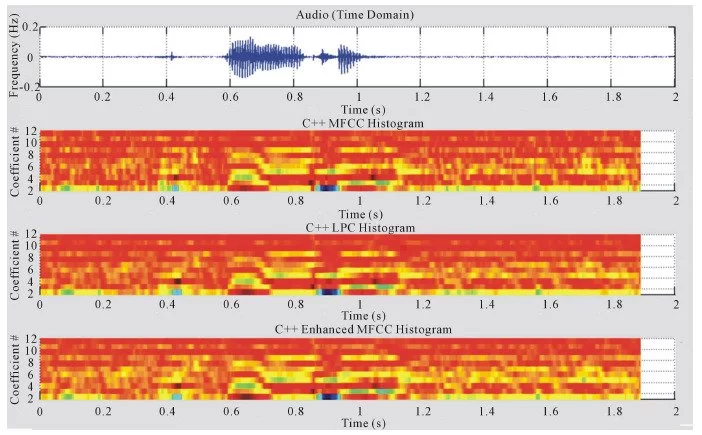
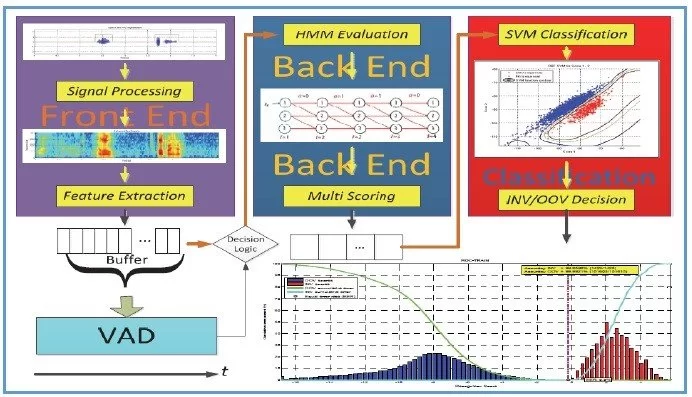
Wake-Up-Word Speech Recognition task (WUW-SR) is a computationally very demand, particu-larly the stage of feature extraction which is decoded with corresponding Hidden Markov Models (HMMs) in the back-end stage of the WUW-SR. The state of the art WUW-SR system is based on three different sets of features: Mel-Frequency Cepstral Coefficients (MFCC), Linear Predictive Coding Coefficients (LPC), and Enhanced Mel-Frequency Cepstral Coefficients (ENH_MFCC). In (front-end of Wake-Up-Word Speech Recognition System Design on FPGA) [1], we presented an experimental FPGA design and implementation of a novel architecture of a real-time spectrogram extraction processor that generates MFCC, LPC, and ENH_MFCC spectrograms simultaneously. In this paper, the details of converting the three sets of spectrograms 1) Mel-Frequency Cepstral Coefficients (MFCC), 2) Linear Predictive Coding Coefficients (LPC), and 3) Enhanced Mel-Fre- quency Cepstral Coefficients (ENH_MFCC) to their equivalent features are presented. In the WUW- SR system, the recognizer’s front-end is located at the terminal which is typically connected over a data network to remote back-end recognition (e.g., server). The WUW-SR is shown in Figure 1. The three sets of speech features are extracted at the front-end. These extracted features are then com- pressed and transmitted to the server via a dedicated channel, where subsequently they are decoded.

التعليقات